1. 기본형 변수(primitive type)
1.1 논리형 - boolean
논리형에는 boolean 한가지 밖에 없다. true, false로 하나만 저장할 수 있으면 디폴트는 false이다.
자바에서는 데이터를 다루는 최소단위가 byte이기 때문에 boolean의 크기는 1byte이다. (8bit =1byte)
자바에서는 대소문자가 구별되기 때문에 True와 true는 다른것으로 간주된다.
1.2 문자형 - char
문자형도 char 한가지 밖에 없다. 또한 char 타입의 변수는 단하나의 문자만을 저장할 수 있다.
//문자 'A'를 char 타입 변수에 저장
char ch = 'A';
//int타입으로 변환해 유니코드 확인
int n = (int)ch;
코드를 보면 변수에 ‘문자’가 저장된 것 같지만 사실은 문자가 아닌 ‘문자의 유니코드(정수)’가 저장된다. 컴퓨터는 숫자밖에 모르기때문에 모든 데이터를 숫자로 변환해 저장한다.
문자 ‘A’의 유니코드는 65기 때문에 변수에는 65가 저장된다. 따라서 문자의 유니코드를 알고 싶으면 char형 변수에 저장된 값을 정수형(int)로 변환하면 된다.
특수문자다루기
영문자 이외에 tab이나 backspace 등의 특수문자를 저장하는 방법이 존재한다.
tab tab
| 특수문자 | 문자 리터럴 |
| tab | tab |
| backspace | \b (백스페이스 삽입 또는 뒤에 문자 제거 ) |
| form feed | \f |
| new line | \n |
| carriage return | \r |
| 역슬래쉬 | \\ |
| 작은따옴표 | \’ |
| 큰따옴표 | \” |
| 유니코드(16진수)문자 | \u유니코드 e.f. char a=’\0041’ |
char타입의 표현형식
char 타입의 크기는 2byte(16bit)이므로 , 16자리의 2진수로 표현할 수 있는 정수의 개수는 2^16인 65536개이다. 따라서 char형 변수는 이 범위 내의 유니코드 중 하나를 저장할 수 있다. 예를들어 문자 ‘A’를 저장하면 아래와 같이 2진수 0000000001000001로 저장된다. (유니코드는 10진수로 65) 따라서 실제로 변수에는 문자가 아닌 문자의 유니코드(정수) 저장되며 표현형식 역시 정수형과 동일하다.
다만 정수형과 달리 char은 음수를 나타낼 필요가 없으므로 char타입에 저장되는 값인 유니코드는 모두 2^6인 65536개이며 범위는 0 ~ 65535개 이다. 반면에 정수형인 short의 타입은 char형과 같은 2byte인데 절반을 음수표현에 사용하므로 -32768 ~ 31767을 범위로 갖는다.
- 2byte = 16비트로 표현할 수 있는 정수의 개수는 2^16
- short 타입의 표현범위 : -2^15 ~ 2^15 -1 (-32768 ~ 32767)
- char 타입의 표현범위 : 0 ~ 2^16 -1 (0~ 65536)
char ch = 'A'; //유니코드 65
short s = 65;
다음과 같이 변수에 값을 저장하면 둘다 컴퓨터에 2진수로 똑같은 값이 저장된다. 그런데 변수를 출력하면 다르게 값이 나오는데 이는 println() 이 변수의 타입에 맞게 출력했기 때문이다. 따라서 값은 어떻게 해석하느냐에 따라 결과가 달라진다.
인코딩과 디코딩
- 인코딩(encoding) : 문자를 코드로 변환
- ‘A’ → 65
- 디코딩(decoding) : 코드를 문자로 변환
- 65 → ‘A’
아스키 코드(ASCII)와 유니코드(Unicode)
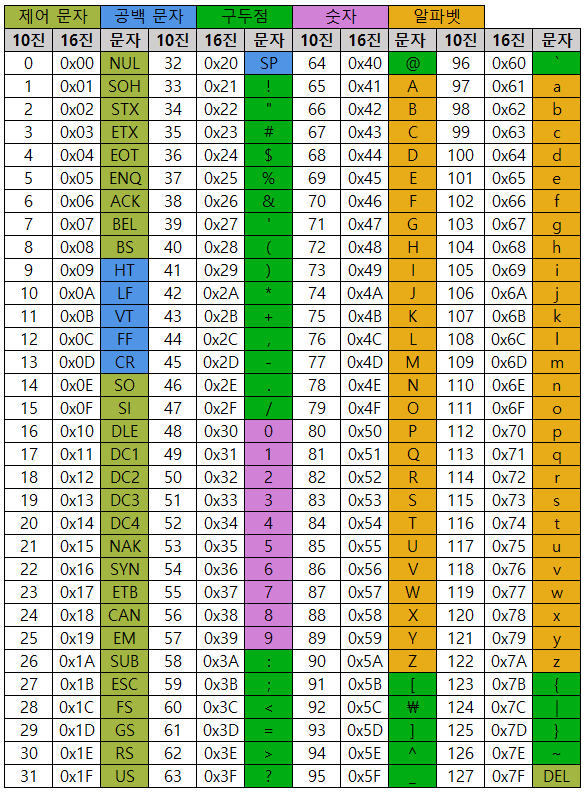
아스키코드는 ‘American Standart Code for Information Interchange’의 약자로 정보교환을 위한 미국 표준 코드를 말한다. 2^7의 문자집합(character set)으로 제공하는 7bit 부호로 기호와 숫가, 영대소문자로 구성되어있다. 숫자 0~ 9, 영문자 A~Z, a~z가 연속적으로 배치되어 있다는 특징이 있다 .
유니코드는 전 세계의 모든 문자를 하나의 통일된 문자집합으로 표현하기 위해 등장하였다. 처음에 문자를 2byte로 표현하려 했으나 부족해서 21bit(약200만 문자)로 확장되었다.
유니코드 포함할 문자들의 집합을 정의했는데, 이것을 유니코드 캐릭터 셋(character set) 이라고 한다. 그리고 이 문자 셋에 번호를 붙인 것이 유니코드 인코딩이다.
유니코드 인코딩에는 UTF_8, UTF16, UTF-32 가 있는데 자바에서는 UTF-16을 사용한다. 그리고 이 UTF-16은 모든 문자를 2byte의 고정크기로 표현하고 UTF-8은 하나의 문자를 1~ 4byte의 가변크기로 표현한다.
이 두 인코딩 모두 처음 128문자가 아스키와 동일하다.
모든 문자의 크기가 동일한 UTF-16이 문자를 다루기는 편리하지만, 1byte로 표현할 수있는 영어와 숫자가 2byte로 표현되므로 문서의 크기가 커진다. 반대로 UTF-8은 영문과 숫자는 1byte, 한글은 3byte로 표현되어 문서의 크기가 작지만 문자의 크기가 가변적이므로 다루기 어렵다는 단점이 있다.
1.3 정수형 - byte, short, int, long
정수형에는 총 4가지 자료형이 있으면 1→ 2→ 4→ 8 byte 순으로 커진다. 기본자료형은 int이다.
정수형의 표현형식과 범위
자바의 모든 정수형은 부호있는 정수이므로 왼쪽의 첫 번째 비트를 부호비트(sign bit)로 사용하고 나머지 비트를 값을 표현하는데 사용한다. 따라서 정리하면
- n비트로 표현할 수 있는 정수 개수 : 2^n 개
- n비트로 표현할 수 있는 부호있는 정수의 범위: -2 ^(n-1) ~ 2^(n-1) -1
부호있는 정수의 범위가 n-1승인 이유는 부호가 있는 정수이므로 맨 첫번째 비트를 부호비트로 사용했기때문이고, 마지막에 양수에서 1을 빼주는 이유는 양수가 0을 포함해서 시작하기 때문이다.
이를 1byte = 8bit 를 예를 들면
- 8비트로 표현할 수 있는 정수의 개수 : 2^8개 (256개)
- 8비트로 표현할 수 있는 부호있는 정수의 범위 : -2^7 ~ 2^7-1 (-128 ~ 127)
정수형의 오버플로우
먼저 해당 타입이 표현할 수 있는 값의 범위를 넘어서는 것을 오버플로우(overflow) 라고한다. 오버플로우가 발생한다고 해서 에러가 발생하는 것은 아니지만 예상했던 결과를 얻지 못한다.
만약 4bit 2진수의 최대값인 ’1111’을 더하면 ‘10000’이 되지만 4bit는 4자리의 2진수만 저장할 수 없기때문이 ‘0000’이 된다. 이렇듯 정수형 타입이 표현할 수 있는 최대값에 1을 더하면 최소값이 되고, 최소값에서 1을 빼면 최대값이 된다. 그래서 값을 무한히 증가시켜도 ‘0000’ ‘1111’ 범위를 계속 반복한다.
부호있는 정수의 오버플로우
부호없는 정수와 부호있는 정수는 표현범위 즉, 최대값과 최소값이 달라서 오버플로우가 발생하는 시점이 다르다.부호없는 정수는 2진수 ‘0000’이 될떄 오버플로우가 발생, 부호있는 정수는 부호비트가 0에서 1이 될때 오버플로욷가 발생한다.
참고로 자바에서는 부호없는 자료형이 ( = 음이 아닌 0과 양수만 표현) char 뿐이며 정수형에서는 부호없는 정수형은 없다.
1.4 실수형 - float, double
실수형의 범위와 정밀도
자바에서는 실수형을 저장하는 타입으로 float,double 이 있다. 위의 범위는 양의 범위만 적은것으로 -부호를 붙이면 음의 범위가 된다. 예를들어 float로 표현가능한 음의 범위는 -1.4 x 10 ^45 ~ -3.4 X 10^38이다.
따라서 float 타입의 표현범위는 -3.4 X 10^38 ~ 3.4 X10^38 이지만, -1.4 X10^45 ~1.4 X 10^-45범위의 값은 표현할 수 없다. (0 제외) 실수형은 소수점수도 표현해야하므로 얼마나 큰 값을 표현할 수 있는가 뿐만 아니라 얼마나 0에 가깝게 표현할 수 있는가도 중요하다.
왜 실수형 float는 같은 4byte인 정수형인 int와 값을 표현할 수 있는 범위가 다를까? 그 이유는 값을 저장하는 형식이 다르기 때문이다. int타입은 부호와 값으로 이루어진것에 비해 float는 부호(S),지수(E),가수(M) 으로 이루어져있다.

따라서 2의 제곱을 곱한형태기 때문에 큰 범위의 값을 저장하는 것이 가능하다. 하지만 정수형과 달리 실수형은 오차가 발생할 수 있다는 단점이 있다. 그래서 실수형은 표현할 수 있는 값의 범위뿐만 아니라 정밀도(precision)이 중요하다 .
float 타입의 정밀도는 7자리, double타입의 정밀도는 15자리인데 따라서 메모리를 절약하려면 float, 높은 정밀도가 필요하면 double 타입을 사용해야한다.
float f = 9.12345678901234567890f;
System.out.printf("f : %f%n", f);//소수점 이하 6째자리까지 출력
System.out.printf("f : %24.20f%n", f);
//결과
//f : 9.123457
//f : 9.12345695495605500000
예시를 보면 %f를 사용하면 기본적으로 소수점 6짜리까지 (7번째에서 반올림) 되어서 출력된다. 그리고 두번째는 전체 24자리 중에서 20자리는 소수점 이하의 수를 출력하라는 뜻이다. 따라서 소수점 밑의 개수가 20개가 되며 앞뒤의 빈자리가 공백과 0으로 채워졌다. 하지만 정밀도가 7자리이므로 9.123456 까지만 정확히 오차없이 출력됐음을 확인 할 수 있다.
실수형의 저장형식
컴퓨터에서 실수를 표현하는 방법은 정수에 비해 훨씬 복잡하다. 왜냐하면 컴퓨터에서는 실수를 정수와 마찬가지로 2지수로만 표현해야하기 때문이다.
- 고정 소수점(fixed point)
- 부동 소수점(floating point)
2가지 방식이 존재하는데 고정 소수점은 정수부와 소수부로 나눌 수 있다. 소수부의 자릿수를 미리 정해서 고정된 자릿수를 소수로 표현하는 방식이다. 하지만 이 방식은 표현할수 있는 범위가 매우 적다는 단점이 있다.
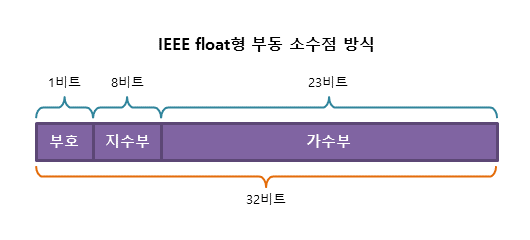
다음 방식은 부동 소수점 방식인데 자바에서 실수형을 표현할때 이 방식을 쓴다. 실수를 가수부와 지수부로 나누어 표현한다. 위의 그림으로 확인할 수있으며 부호(Sign), 지수(Exponent), 가수(Mantissa) 모두 세 부분으로 이루어져 있다.
- 부호 : 부호비트를 의미. 정수형과 달리 2의 보수법을 사용하지 않기때문에 양의 실수를 음의 실수로 바꾸려면 부호비트만 변경하면 된다.
- 지수 : 지수를 저장하는 공갑으로 float의 는 8bit의 저장공간아 총 256개의 값을 저장할 수 있다.
- 가수: 실제 값인 가수를 저장하는 부분으로 2진수 23자리를 저장할 수 있다. 2진수 23자리로는 7자리의 10진수를 저장할 수있는데 이것이 바로 float의 정밀도가 된다.
실수형의 오버플로우
정수형과 달리 실수형에서는 오버플로우가 발생하면 변수의 값은 무한대가 된다. 그리고 정수형에는 존재하지 않는 언더플로우(underflow)가 있는데 언더플로우는 실수형으로 표현할 수 없는 아주 작은 값. 즉 양의 최소값보다 작은 값이 되는 경우를 말한다.
출처 : 자바의 정석
'Java' 카테고리의 다른 글
| [JAVA] 객체지향 프로그래밍 - 클래스와 객체 (0) | 2023.12.19 |
|---|---|
| [JAVA] 형변환(캐스팅, casting) (0) | 2023.12.17 |
| [JAVA] 진법과 2의 보수법 (1) | 2023.12.07 |
| [JAVA] 변수와 변수의 타입 (1) | 2023.12.07 |
| [JAVA] TreeMap (1) | 2023.12.07 |